
よっしー
こんにちは。よっしーです(^^)
今日は、Kubernetes Engine での Cloud Loggingについて解説しています。
スポンサーリンク
背景
下記の記事の続きになります。

実施内容
下記のコマンドを実行します。
make validate下記のような出力になれば成功です。
Step 1 of the validation passed. App is deployed.
App is available at: http://xxx.xxx.xxx.xxx:8080
Step 2 of the validation passed. App handles requests.ブラウザで「http://xxx.xxx.xxx.xxx:8080」にアクセスすると下記のような出力になります。

ロギングの確認
- Cloud コンソールのナビゲーション メニューで、[オペレーション] にある [ロギング] をクリックします。
- このページで、
Resource typeは [Kubernetes コンテナ]、cluster_nameは [stackdriver-logging] を選択します。

ログ エクスポートの表示
- 引き続き [ロギング] ページを使用します。
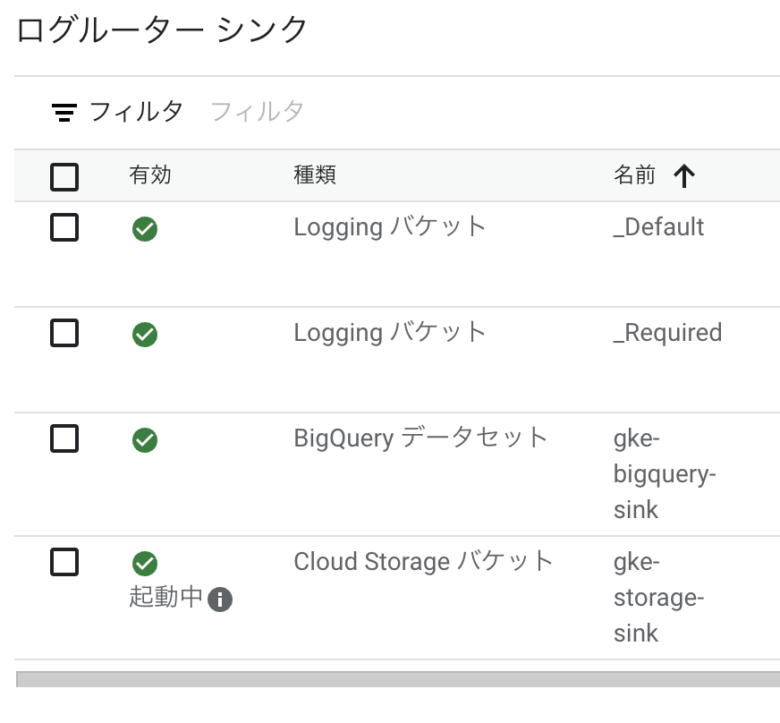
- 左側のナビゲーション メニューで [ログルーター] をクリックします。
- ログ エクスポートの一覧に 4 つのシンクがあるのを確認します。
- シンクの右側にあるコンテキスト メニュー(その他アイコン)をクリックし、[シンクを編集] オプションを選択すると、シンクを表示して編集できます。
- ナビゲーション ウィンドウの上部にある [シンクの作成] オプションをクリックすれば、追加のカスタム エクスポート シンクを作成することもできます。
Cloud Storage におけるログ
- Cloud コンソールのナビゲーション メニューで [Cloud Storage] をクリックします。
stackdriver-gke-logging-<random-Id>という名前のバケットを見つけてクリックします。- シンクが Cloud Storage に反映されるまでには時間がかかるため、バケットのログの詳細は表示されない可能性があります。
BigQuery におけるログ
- ナビゲーション メニューの [ビッグデータ] で [BigQuery] をクリックします。[
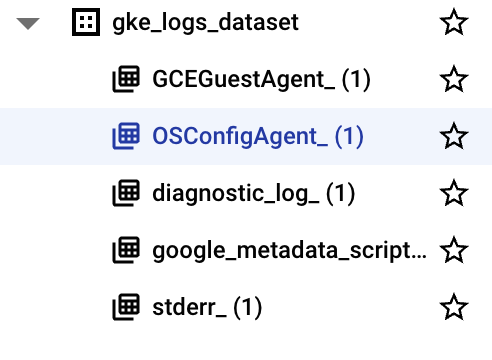
Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開いたら、[完了] をクリックします。 - 左側のメニューで、使用するプロジェクト名をクリックします。gke_logs_dataset というデータセットが表示されます。このデータセットを展開すると、存在するテーブルを確認できます(注: データセットはすぐに作成されますが、テーブルはログが書き込まれて新しいテーブルが必要になった時点で生成されます)。
- テーブルの一つをクリックして内容を表示します。
- テーブルのスキーマを見て、列の名前とデータ型を確認します。この情報は、次のステップでテーブルにクエリを実行してデータを調べるときに使います。
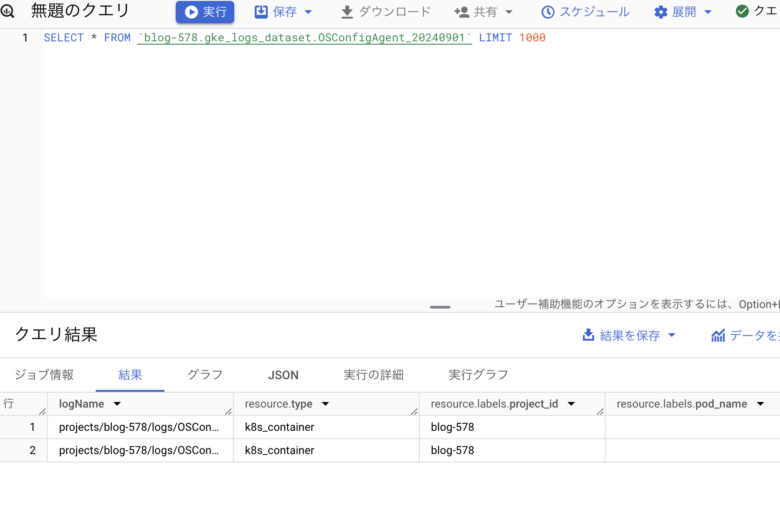
- 右上にある [クエリ] > [新しいタブ] をクリックして、テーブルに対してカスタムクエリを実行します。
- これでクエリがクエリエディタに追加されますが、このクエリには構文エラーがあります。
- クエリを編集し、Select の後にアスタリスク(*)を追加して、現在のテーブルからすべての情報が pull されるようにします。注:
Select *クエリを実行すると一般にコストが高くなるので、おすすめしません。このラボで使うデータセットには直近 1 時間分のログしか含まれないため、データの量は多くありません。 - [実行] をクリックしてクエリを実行し、テーブルから結果を取得します。
解説
シンクとは
シンク(Sink)は、Google Cloud のログ管理システムの重要な機能の一つです。主にCloud Logging(以前はStackdriver Loggingと呼ばれていました)で使用されます。
シンクの主な特徴と用途は以下の通りです:
- 定義:
シンクは、ログエントリを外部の宛先にエクスポートするための設定です。 - 目的:
- ログデータの長期保存
- 詳細な分析のためのデータ収集
- 他のシステムとの統合
- コンプライアンス要件の満たす
- 宛先タイプ:
シンクは以下の宛先にログを送ることができます:
- Cloud Storage:長期保存用
- BigQuery:詳細な分析用
- Pub/Sub:リアルタイム処理や他のシステムとの統合用
- 別のGoogle Cloudプロジェクトのログバケット
- フィルタリング:
シンクはフィルタを使用して、特定の条件に合致するログのみをエクスポートすることができます。 - IAM(Identity and Access Management):
シンクには独自のサービスアカウントが割り当てられ、適切な権限を持つ必要があります。 - Terraformでの設定例:
resource "google_logging_project_sink" "my-sink" {
name = "my-sink"
destination = "storage.googleapis.com/${google_storage_bucket.log-bucket.name}"
filter = "severity >= WARNING"
}- 利点:
- 中央集中型のログ管理
- 柔軟なデータ保持ポリシー
- 高度な分析と可視化の可能性
- セキュリティとコンプライアンスの向上
- 注意点:
- エクスポートされたログのボリュームに応じて追加のコストが発生する可能性があります。
- 適切なIAM権限の設定が重要です。
シンクを使用することで、GCPのさまざまなサービスから生成されるログを効率的に管理し、長期保存や詳細な分析を行うことができます。これは、トラブルシューティング、セキュリティ監査、パフォーマンス最適化などに非常に有用です。
おわりに
今日は、Kubernetes Engine での Cloud Loggingについて解説しました。
よっしー
何か質問や相談があれば、コメントをお願いします。また、エンジニア案件の相談にも随時対応していますので、お気軽にお問い合わせください。
それでは、また明日お会いしましょう(^^)


コメント