
こんにちは。よっしーです(^^)
今日は、Breakpoint testing についてご紹介します。
背景
Dockerで構築したWebアプリの開発環境において、k6を利用した負荷テストについて調査したときの内容を備忘として残しました。
開発環境のソースは下記のリポジトリにあります。
ブレークテスト(Breakpoint testing)
ブレークポイントテストは、システムの限界を見つけることを目的としています。限界を知りたい理由には以下のようなものがあります:
- システムの弱点を調整またはケアし、それらの上限を高いレベルに再配置するため。
- これらのケースでの対策ステップを計画し、システムがこれらの限界に近づいたときに備えるため。
つまり、システムがどこでどのように失敗し始めるかを知ることは、そのような限界に備えるのに役立ちます。
ブレークポイントテストは、非現実的に高い数値までランプアップします。このテストは、しきい値が失敗し始めると手動または自動で停止する必要があることが一般的です。これらの問題が現れると、システムはその限界に達しています。
ブレークポイントテストは、明確な命名の合意がない別のテストタイプです。テストの会話では、容量テスト、ポイント負荷テスト、制限テストとも呼ばれることがあります。
ブレークテストを実行するタイミング
チームは、システムのさまざまな限界を知る必要がある場合に、ブレークポイントテストを実行します。ブレークポイントテストを実行する必要がある可能性がある条件には、以下のようなものがあります:
- システムの負荷が持続的に増加するかどうかを知る必要がある場合。
- 現在のリソース消費が高いと考えられる場合。
- コードベースやインフラストラクチャに重大な変更が加えられた後。
このテストタイプをどのくらいの頻度で実行するかは、システムの限界に達するリスクと、インフラストラクチャのコンポーネントを提供するための変更の数に依存します。
ブレークポイントテストを実行し、システムの限界が特定されたら、調整作業の後にテストを繰り返して、それが限界にどのように影響を与えたかを検証できます。チームが満足するまで、テストと調整のサイクルを繰り返します。
考慮事項
弾力的なクラウド環境ではブレークポイントテストを避けてください。
弾力的な環境では、テストが進行するにつれて環境が成長し、クラウドアカウントの料金制限だけが限界になる可能性があります。このテストをクラウド環境で実行する場合、影響を受けるすべてのコンポーネントの弾力性を無効にすることを強くお勧めします。
負荷を徐々に増加させてください。
急激な増加は、システムがなぜどのタイミングで失敗し始めるかを特定するのが難しくなる可能性があります。
システムの失敗は、異なるチームにとって異なる意味を持つかもしれません。
次の各種の失敗ポイントを特定したいかもしれません:
- パフォーマンスの劣化。応答時間が増加し、ユーザーエクスペリエンスが低下します。
- 問題のあるパフォーマンス。応答時間がユーザーエクスペリエンスが著しく低下するポイントに達します。
- タイムアウト。過度に高い応答時間のためにプロセスが失敗します。
- エラー。システムがHTTPエラーコードで応答し始めます。
- システムの崩壊。システムが崩壊します。
このテストは何度も繰り返すことができます。
チューニングごとに繰り返すことで、システムをさらに限界まで推進することができるかもしれません。
ブレークポイントテストは、システムが他のすべてのテストタイプで正常に実行されることがわかっている場合にのみ実行してください。
前のテストタイプでシステムのパフォーマンスが低い場合、ブレークポイントテストは遠くまで進む可能性があります。
Breakpoint testing in k6
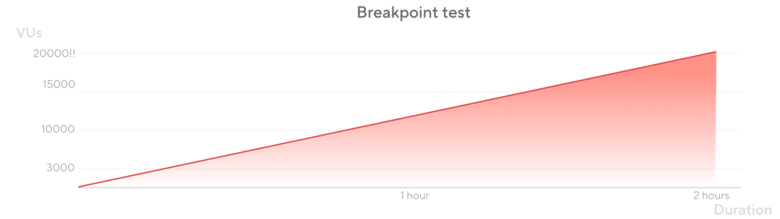
ブレークポイントテストは非常にシンプルです。負荷がゆっくりとかなり高いレベルに増加します。フルロード、ランプダウン、その他のステップはありません。そして、通常、指定されたポイントに到達する前に失敗します。
k6はアクティビティを増加させるために2つの方法を提供しています:VU(Virtual User)を増加させること、またはスループットを増加させること(オープンモデルとクローズドモデル)。他の負荷テストタイプとは異なり、システムが特定のポイントまで劣化するとテストを停止すべきであるという考え方とは異なり、ブレークポイントテストではシステムが劣化し始めても負荷が増加し続けることがあります。そのため、ブレークポイントテストでは「ramping-arrival-rate」を使用することがおすすめされます。
このテストは、定義されたブレークポイントまたはシステムの限界に到達するまで負荷またはVUsを増加し続け、その時点でテストを停止または中断します。
import http from 'k6/http';
import {sleep} from 'k6';
export const options = {
// Key configurations for breakpoint in this section
executor: 'ramping-arrival-rate', //Assure load increase if the system slows
stages: [
{ duration: '2h', target: 20000 }, // just slowly ramp-up to a HUGE load
],
};
export default () => {
const urlRes = http.get('https://test-api.k6.io');
sleep(1);
// MORE STEPS
// Here you can have more steps or complex script
// Step1
// Step2
// etc.
};
テストは、予定された実行を完了する前に停止する必要があります。テストを手動で停止するか、しきい値を使用して停止できます:
- k6をCLIで手動で停止するには、LinuxまたはWindowsでCtrl+Cを、MacでCommand+.を押します。
- しきい値を使用してテストを停止する場合、abortOnFailをtrueとして定義する必要があります。詳細については、しきい値に関するドキュメントを参照してください。
結果の分析
ブレークポイントテストは、システムの障害を引き起こす必要があります。このテストは、システムの障害ポイントを特定し、システムが限界に達したときの挙動を把握するのに役立ちます。
システムの限界が特定されたら、チームには2つの選択肢があります:それを受け入れるか、システムを調整するかです。
限界を受け入れる決定をする場合、テストの結果は、システムがそのような限界に近づいているときに備えて行動するのにチームに役立ちます。
これらのアクションは次のようになる可能性があります:
- 限界に到達しないように予防する。
- システムリソースを拡充する。
- 限界でのシステムの挙動に対する修正措置を実施する。
- システムを調整してその限界を広げる。
アクションがシステムを調整することに決まった場合、調整を行い、その後ブレークポイントテストを繰り返してシステムの限界がどこに移動し、限界がどの程度調整できるかを見つけます。
チームは、ブレークポイントテストの繰り返し回数、システムを調整できる範囲、および各演習後の限界の調整幅を決定する必要があります。
おわりに
今日は、Breakpoint testingについてご紹介しました。
何か質問や相談があれば、コメントをお願いします。また、エンジニア案件の相談にも随時対応していますので、お気軽にお問い合わせください。
それでは、また明日お会いしましょう(^^)


コメント